2024年11月,国家卫生健康委、国家中医药局、国家疾控局联合印发的《卫生健康行业人工智能应用场景参考指引》,为人工智能在医疗领域的应用指明了方向,旨在利用人工智能技术提升疾病早筛、影像数据分析、诊断精度等多方面的水平,推动医学影像科研与成果转化,同时减轻医生工作压力和优化医院人力成本。
随着DeepSeek陆续开源高性能、低成本模型,全国各地的医院、卫健委等医疗卫生机构正积极进行人工智能应用的密集部署,医疗信息化企业、研究院所也正全力推出相关算力产品和服务,以提升医疗服务的效率与质量,标志着医疗AI从技术验证迈向规模化应用。
与此同时,医疗大模型的引入也给行业内的医疗机构和管理机构带来一些风险与挑战。例如,诊断准确率受限于训练数据质量,罕见病案例覆盖不足可能产生漏诊;存在“幻觉”现象,可能产生错误的诊断、治疗建议或医疗决策;甚至可能引发医学伦理、药物禁忌等问题导致的临床医疗事故等等。因此,医疗大模型的性能和可靠性成为了关键关注点。
中国软件评测中心联合上海人工智能实验室,基于司南大模型开放评测体系MedBench医疗大模型评测基础及经验,推出医疗大模型基础服务能力评测服务。该服务依托顶级医疗机构的专家经验和知识储备,并结合自动化评测技术,建立了医疗大模型基础服务能力评测体系,全面评估医疗大模型基本性能和可靠性,为企业产品提供专业的性能评估与优化建议,提升产品竞争力;为行业用户提供权威、可靠的选型参考,确保切实满足业务需求,推动卫生健康行业人工智能应用效能提升,促进整个卫生健康行业的智能化发展与变革。
一、测评内容
本次测评将依托由中国软件评测中心、上海人工智能实验室联合推进的医疗大模型基础服务能力评测体系,面向医疗大模型产品的软件质量检测及大模型能力评测,分别从功能完备性、性能效率等指标,以及模型通用基础能力及安全性、医疗伦理安全及有害性、医药理论知识掌握能力、临床诊疗实践能力等多方面开展测试评估。同时也可进行定向委托,针对医疗大模型在指定医疗场景的应用服务能力验证。
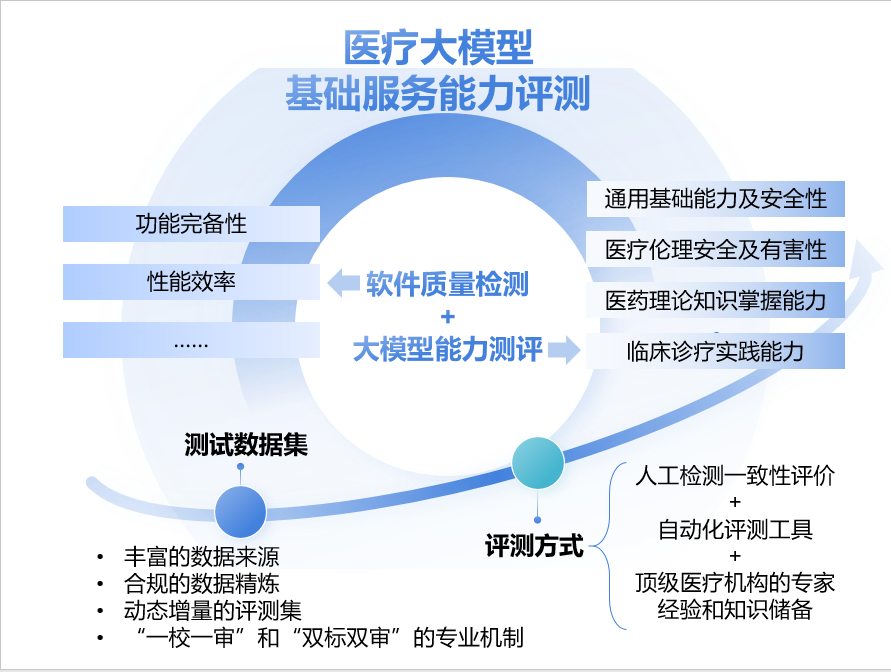
(一)软件质量检测包括但不限于:
1)功能完备性:从大模型的功能表现、正确性、截断率、易用性、用户体验以及和需求的一致性等方面进行检测;
2)性能效率:主要检测大模型吞吐量、完整回复率、吞吐速率,以及在业务繁忙情形下系统的并发响应速度等;
(二)大模型能力测评:
1)通用基础能力及安全性:主要考察大模型本身处理各种任务的能力,如逻辑推理、上下文处理等;安全性主要包括大模型的内容安全性、鲁棒性、可控性等方面的检测;
2)医疗伦理安全及有害性:主要检测医疗大模型的医学伦理、药物禁忌等方面;
3)医药理论知识掌握能力:主要检测大模型对医学知识的深度理解和分析能力,包括对解剖学、生理学、病理学、药理学等基础医学理论的掌握程度,以及对医药数据的智能处理和分析能力。
4)临床诊疗实践能力:主要检测多模态诊断推理、动态病程预测、个性化治疗规划、实时决策支持、医患交互增强等方面。
一、面向对象
(一)行业侧:为卫健委、医院等医疗卫生机构提供医疗大模型产品基础服务能力测试及应用服务能力验证服务。
(二)企业侧:为医疗信息化企业、AI技术公司、科研院所等研发机构提供医疗大模型产品基础服务能力测评验证服务。
二、测评安排
测评报名:即日起开始
首批测评工作开展:2025年2-4月
第二批测评工作开展:2025年5月起
三、业务咨询
王老师15801567456(微信同号)
沈老师13831710767(微信同号)
杨老师15010559926(微信同号)
